Steven Schwartz was 30 years into his legal career when ChatGPT ended it. Well, almost ended it. He kept his license. He paid a $5,000 sanction. His name went on a federal court order that anyone Googling "AI lawyer sanctioned" will find for the rest of his life.
The case was Mata v. Avianca. Schwartz, an attorney at Levidow, Levidow & Oberman, filed a brief in the Southern District of New York citing six federal cases that supported his client's position. The cases were perfect. The citations looked clean. The reasoning tracked.
None of the cases existed. ChatGPT invented all six. Schwartz had asked the chatbot whether the cases were real. ChatGPT confirmed they were. He filed the brief.
Judge P. Kevin Castel was not amused.
The $5,000 sanction that should have changed everything
Most coverage of Mata focuses on the embarrassment. The lawyer cried in court. The story went viral. Late-night hosts did jokes about it. But the legal consequence was straightforward: sanctions under Rule 11 of the Federal Rules of Civil Procedure for filing a brief with no reasonable inquiry into the truth of its citations.
What people missed: the duty Schwartz violated did not exist because of AI. It existed because of every signature on every brief he had ever filed. Rule 11 requires that an attorney certify the legal contentions are warranted by existing law or a non-frivolous argument for extending it. ChatGPT did not break that rule. Schwartz did, by trusting the output without verifying.
That should have been a one-time incident. A cautionary tale. The legal profession would learn from it and move on.
It was not. Since June 2023, attorneys have been sanctioned in at least a dozen additional cases for filing AI-generated content with hallucinated citations. The pattern is identical every time. A lawyer asks ChatGPT for case law. ChatGPT generates citations that sound plausible. The lawyer files without checking. The opposing counsel or the court catches it. The lawyer is sanctioned.
Why ChatGPT lies, and calls it confidence
The technical term for what ChatGPT does in these cases is "hallucination." It is a polite word. What it means: the model generates text that is fluent, confident, and false. There is no internal mechanism that says "I do not know this case, so I will not cite it." The model just predicts the next likely word in a sequence, over and over, until it has produced something that reads like a legal citation.
This is not a bug. It is how large language models work. ChatGPT was trained on enormous quantities of text from the internet. Some of that text was real case law. A lot of it was discussion of case law, summaries of cases, references to cases. When you ask the model for a citation, it produces something that looks like every citation it has seen. The pattern of a federal reporter cite. The structure of a case caption. The cadence of legal argument.
None of that requires the underlying case to exist.
If you ask a paralegal for a case citation and they do not know one, they tell you they do not know. ChatGPT does not have that option. The model always produces output. If the truthful output would be "I have no relevant cases," the model has no way to express that. So it makes something up.
The cruelest part is the confidence. The model writes the fake citation in exactly the same tone as a real one. There is no hedging. No "I think this case might be" or "you should verify." Just clean, confident, completely fabricated authority.
The cases since Mata that did not make headlines
Mata got the press because it was first. The cases since have been quieter, but they keep coming.
In Park v. Kim (Second Circuit, January 2024), the court referred attorney Jae S. Lee to the bar's grievance panel after she cited a nonexistent case in an appellate brief. The case she cited, Matter of Bourguignon v. Coordinated Behavioral Health Services, did not exist. Lee admitted she used ChatGPT and did not verify.
In Morgan v. Community Against Violence (D.N.M., November 2023), counsel was ordered to show cause why he should not be sanctioned after citing cases that "appear to be fictitious." He used ChatGPT to draft the response. The court was not persuaded by his apology.
In Ex parte Lee (Texas Court of Criminal Appeals, 2024), a criminal defense attorney filed a writ application with fabricated citations generated by an AI tool. The Texas bar opened an inquiry. The conviction was unaffected. The lawyer's reputation was not.
These cases are not outliers. They are the visible part of an iceberg. For every sanctioned attorney, there are dozens whose hallucinated filings were caught by an attentive associate, a careful paralegal, or opposing counsel doing their job. The errors that get found embarrass everyone. The errors that do not get found end up in the public record.
What "AI legal research" actually means at most firms
Talk to any managing partner about AI right now and you will hear some version of the same statement. We have a policy. We do not allow ChatGPT for client work. Our associates know better.
Then you talk to the associates.
The associates use ChatGPT. They use it for first drafts of motions. They use it to summarize depositions. They use it to brainstorm arguments. Some of them are careful and verify everything. Some of them are exhausted at 11pm and trust the output more than they should. The policy exists. The behavior continues anyway because the policy gives no alternative.
Here is the honest truth nobody at most firms wants to say out loud. ChatGPT is genuinely useful for legal work. The risk is not that AI cannot help lawyers. The risk is that the wrong AI helps them in dangerous ways.
What lawyers actually need is an AI that knows their firm's documents, cites every claim back to a source, and refuses to invent material it does not have. That product exists. It is not called ChatGPT.
The three things a private legal AI does that ChatGPT cannot
I co-founded DVLP Studio and we build a product called DVLPstudio Legal Intelligence. Full disclosure on the bias. But the three things I am about to describe are not unique to our product. They are the requirements that any AI tool deployed in legal practice has to satisfy.
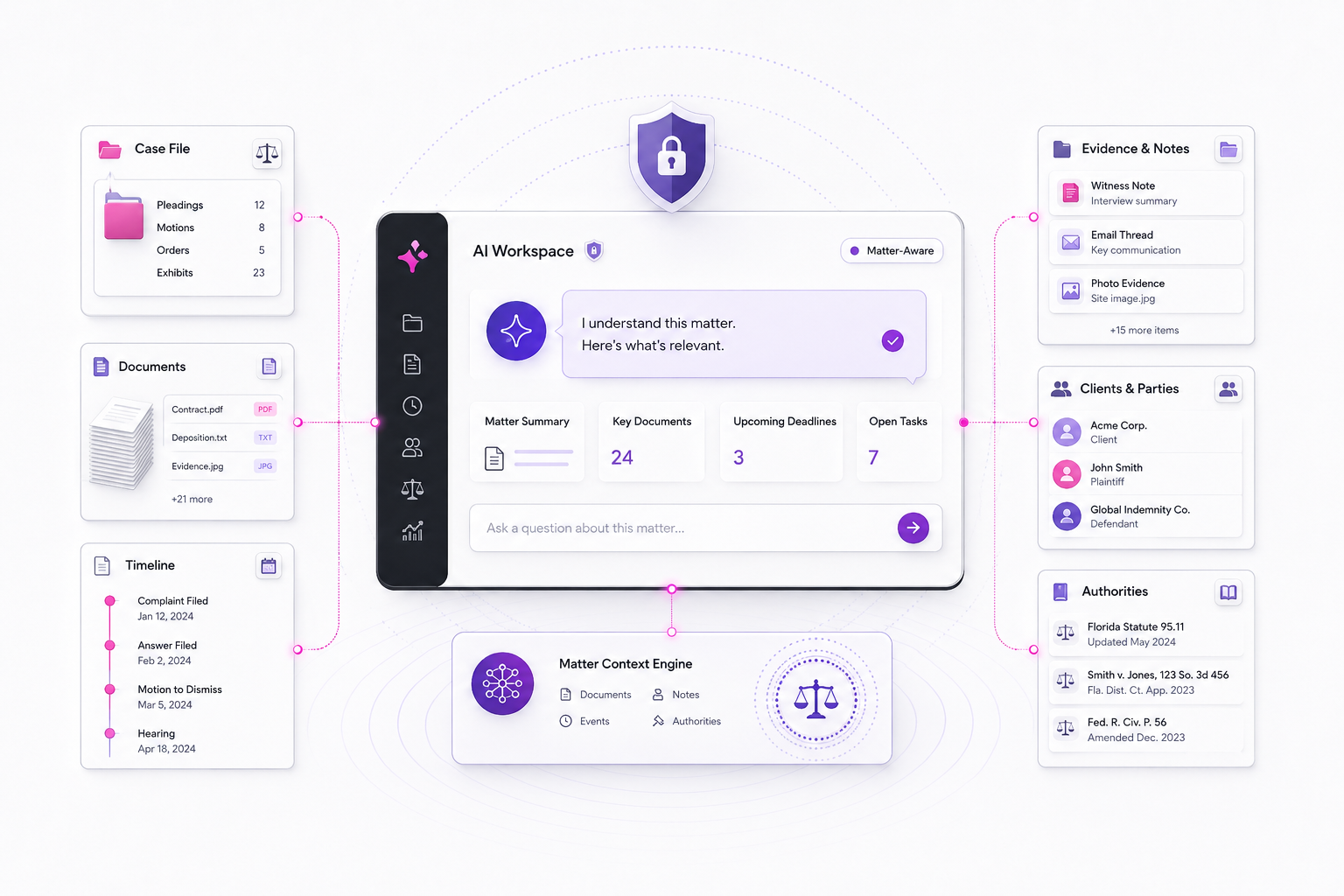
First, it has to be grounded in your actual documents. ChatGPT generates from its training data, which includes the internet but not your firm's templates, your closed cases, or your tone profile. A private legal AI works from a knowledge base your firm owns. When it produces a draft, the draft is built from documents you uploaded. When it cites a case, that case is in your library or it is a verifiable external source. The model is not pulling from a probabilistic memory of the public internet.
Second, every output has to cite its source. A legal AI that cannot tell you which document an answer came from is not suitable for legal practice. The supervision duty under ABA Model Rule 5.3 effectively requires it. If your associate cannot trace a paragraph in a draft back to a specific source document, you cannot supervise the work. ChatGPT does not cite. A real legal AI cites every claim, links to the page, and lets the lawyer verify in seconds.
Third, it has to know the case you are working on. Generic AI starts every conversation cold. If you are working on a specific matter, you have to re-explain the client, the practice area, and the facts at the start of every chat. A matter-aware AI lets you pin a case to your conversation. The AI uses that context in every answer. It will not confuse one client's facts for another's. It will not invent case-specific details it does not have. It knows what it does not know.
What to use instead
If you are a managing partner reading this, here is the practical move. Stop trying to ban a tool your associates already use. Replace it with one that works.
The criteria for a private legal AI you can actually deploy in client work, taken from the requirements ABA Formal Opinion 512 effectively imposes, look like this. Your firm's data is isolated from other firms. The vendor does not use your queries or documents to train models. Every output cites its source. There is a written supervision policy. Engagement letter language exists for AI disclosure. You can verify all of this in writing, in the data processing agreement, before you sign.
If a vendor cannot answer those questions clearly, they are not ready to handle legal work. If they can, you are looking at the right category of tool.
For practices that run on volume and pattern recognition, like Social Security disability, immigration, or personal injury, the value compounds quickly. Pre-hearing briefs drafted from your firm's templates. RFC analyses cited to specific medical records. Onset date strategy informed by your prior cases. We built DVLPstudio Legal Intelligence for SSD attorneys specifically around this kind of workflow.
If you want to talk through how your firm should think about this, get on a call. I will be direct about whether our product is the right fit, and tell you who else to look at if it is not. Either way, do not let the next ChatGPT sanction land on someone at your firm. That is a story you do not want under your name.